أيها الرب يسوع المسيح، طبيب النفوس والأجساد، نرفع قلوبنا إليك في هذه اللحظات متضرعين لأجل ابنتك وخادمتك الأمينة، "أمة نائبة الاشراف العام". نشكرك يا رب على كل ما صنعته وتصنعه في حياتها، وعلى أمانتها في الخدمة التي ائتمنتها عليها.
يا صانع العجائب، نضع بين يديك المباركتين هاتين العمليتين الجراحيتين لعيينيها. نسألك أن تبسط يمينك الحانية وتشفيها، وتمنح الأطباء والطاقم الطبي حكمة ومعرفة ويداً ماهرة، لكي تكلل كل خطوة وكل إجراء بالنجاح التام. كما صليت يا رب وفتحت أعين العميان، نطلب منك أن تلمس عينيها بلمسة شفاء إلهية، وتنزع عنها كل ألم، وضعف، وخوف.
نصلي يا رب من أجل سلامك الذي يفوق كل عقل، ليملأ قلبها وذهنها، ولتكن هي وكل محبيها في طمأنينة وثقة في عملك العجيب. احفظها في فترة النقاهة، وبارك في صحتها، لتستعيد عافيتها وقوتها بالكامل.
يا راعي الخراف الصالح، اشتقنا لعودتها بالسلامة إلى كرمك المقدس لتكمل رسالتها وخدمتها التي تحبها. اجعلها منارة مضيئة تشهد لمجدك، واملأها بروحك القدوس لتستمر في العطاء والبذل باسمك القدوس.
أيتها العذراء الفائقة القداسة، يا شفاء المرضى وملجأ المتألمين، نأتي إليكِ اليوم واضعين أمام قلبكِ الوالديّ الحنون خادمة المسيح الأمينة، نائبة الإشراف العام "أمة".
يا أم النور، يا من حملتِ في أحشائكِ ينبوع الحياة، نرفع عيوننا وعيونها إليكِ، متوسلين أن تمدّي يَدَكِ الطاهرة وغير المنظورة فوق عينيها. باركِ يا أمي يديّ الجراحين وكل الفريق الطبي، لكي يكونوا أداةً لشفائها ونجاح العمليتين الجراحيتين.
أنتِ التي اختبرتِ أوجاع الألم، احفظي خادمتكِ "أمة" في سلامكِ الذي يفوق كل عقل، وامنحيها نعمة الصبر والقوة لتجتاز فترة النقاهة بنجاح. نشكركِ يا مريم لأنكِ لا تردّين من يلتجئ إلى حمايتكِ. نحن نثق في عنايتكِ وشفاعتكِ، منتظرين عودتها الميمونة لتواصل عملها وخدمتها المباركة في كرمة الرب بفرحٍ وتهليل.
بشفاعة قلبكِ الطاهر، وباسم مخلصنا وفادينا يسوع المسيح، نرفع هذه الصلوات.
آمين.
أيّها الرّوح القدس، المعزّي الصّالح، هلمّ وأرسل من السّماء شعاع نورك الإلهي . يا ضياء القلوب العذب ، نضع بين يديك خادمتك الأمينة "أمة" نائبة الإشراف العام، التي كرّست حياتها ومحبتها لخدمة كلمتك.
نسألك يا رب أن تمدّ يمينك القدّوسة وتلمس عينيها، لتُجري بيدكَ الشّافية كلّ نجاحٍ وكمالٍ في العمليتين اللتين أجرتهما. يا من قال: "أنا هو نور العالم"، نوّر بصيرتها، واشفِ كلَّ ضعفٍ، وامنح الأطباء حكمةً ومعرفةً لتكون يداك هما العاملتان في كلّ خطوة. هبْ جسدها الصّحة، وعافِيتها القوة، لتستردّ عافيتها بالكامل.
أيّها الرّوح القدس، يا مُعطي المواهب ، املأ قلبها بسلامك الذي يفوق كلّ عقل . ثبّتها في الإيمان، وامنحها طمأنينة الرّوح في فترة نقاهتها. نحن ننتظر بشوقٍ وفرحٍ عودتها الميمونة والمباركة إلى حقول خدمتها، لتمجّد اسمك القدّوس وتشهد لأعمالك العجيبة.
نشكرك، يا روح الله، لأنك تسمع وتستجيب، وتحفظ خادمتك في ستر جناحيك . بنعمتك وقوّتك، نُسلّمها لك، وإلى أبد الآبدين. آمين
نشكرك يا رب لأنك تسمع وتستجيب، لأنك أنت هو هو أمس واليوم وإلى الأبد. بشفاعة أمنا العذراء مريم، وجميع قديسيك.
آمين
يا صانع العجائب، نضع بين يديك المباركتين هاتين العمليتين الجراحيتين لعيينيها. نسألك أن تبسط يمينك الحانية وتشفيها، وتمنح الأطباء والطاقم الطبي حكمة ومعرفة ويداً ماهرة، لكي تكلل كل خطوة وكل إجراء بالنجاح التام. كما صليت يا رب وفتحت أعين العميان، نطلب منك أن تلمس عينيها بلمسة شفاء إلهية، وتنزع عنها كل ألم، وضعف، وخوف.
نصلي يا رب من أجل سلامك الذي يفوق كل عقل، ليملأ قلبها وذهنها، ولتكن هي وكل محبيها في طمأنينة وثقة في عملك العجيب. احفظها في فترة النقاهة، وبارك في صحتها، لتستعيد عافيتها وقوتها بالكامل.
يا راعي الخراف الصالح، اشتقنا لعودتها بالسلامة إلى كرمك المقدس لتكمل رسالتها وخدمتها التي تحبها. اجعلها منارة مضيئة تشهد لمجدك، واملأها بروحك القدوس لتستمر في العطاء والبذل باسمك القدوس.
أيتها العذراء الفائقة القداسة، يا شفاء المرضى وملجأ المتألمين، نأتي إليكِ اليوم واضعين أمام قلبكِ الوالديّ الحنون خادمة المسيح الأمينة، نائبة الإشراف العام "أمة".
يا أم النور، يا من حملتِ في أحشائكِ ينبوع الحياة، نرفع عيوننا وعيونها إليكِ، متوسلين أن تمدّي يَدَكِ الطاهرة وغير المنظورة فوق عينيها. باركِ يا أمي يديّ الجراحين وكل الفريق الطبي، لكي يكونوا أداةً لشفائها ونجاح العمليتين الجراحيتين.
أنتِ التي اختبرتِ أوجاع الألم، احفظي خادمتكِ "أمة" في سلامكِ الذي يفوق كل عقل، وامنحيها نعمة الصبر والقوة لتجتاز فترة النقاهة بنجاح. نشكركِ يا مريم لأنكِ لا تردّين من يلتجئ إلى حمايتكِ. نحن نثق في عنايتكِ وشفاعتكِ، منتظرين عودتها الميمونة لتواصل عملها وخدمتها المباركة في كرمة الرب بفرحٍ وتهليل.
بشفاعة قلبكِ الطاهر، وباسم مخلصنا وفادينا يسوع المسيح، نرفع هذه الصلوات.
آمين.
أيّها الرّوح القدس، المعزّي الصّالح، هلمّ وأرسل من السّماء شعاع نورك الإلهي . يا ضياء القلوب العذب ، نضع بين يديك خادمتك الأمينة "أمة" نائبة الإشراف العام، التي كرّست حياتها ومحبتها لخدمة كلمتك.
نسألك يا رب أن تمدّ يمينك القدّوسة وتلمس عينيها، لتُجري بيدكَ الشّافية كلّ نجاحٍ وكمالٍ في العمليتين اللتين أجرتهما. يا من قال: "أنا هو نور العالم"، نوّر بصيرتها، واشفِ كلَّ ضعفٍ، وامنح الأطباء حكمةً ومعرفةً لتكون يداك هما العاملتان في كلّ خطوة. هبْ جسدها الصّحة، وعافِيتها القوة، لتستردّ عافيتها بالكامل.
أيّها الرّوح القدس، يا مُعطي المواهب ، املأ قلبها بسلامك الذي يفوق كلّ عقل . ثبّتها في الإيمان، وامنحها طمأنينة الرّوح في فترة نقاهتها. نحن ننتظر بشوقٍ وفرحٍ عودتها الميمونة والمباركة إلى حقول خدمتها، لتمجّد اسمك القدّوس وتشهد لأعمالك العجيبة.
نشكرك، يا روح الله، لأنك تسمع وتستجيب، وتحفظ خادمتك في ستر جناحيك . بنعمتك وقوّتك، نُسلّمها لك، وإلى أبد الآبدين. آمين
نشكرك يا رب لأنك تسمع وتستجيب، لأنك أنت هو هو أمس واليوم وإلى الأبد. بشفاعة أمنا العذراء مريم، وجميع قديسيك.
آمين
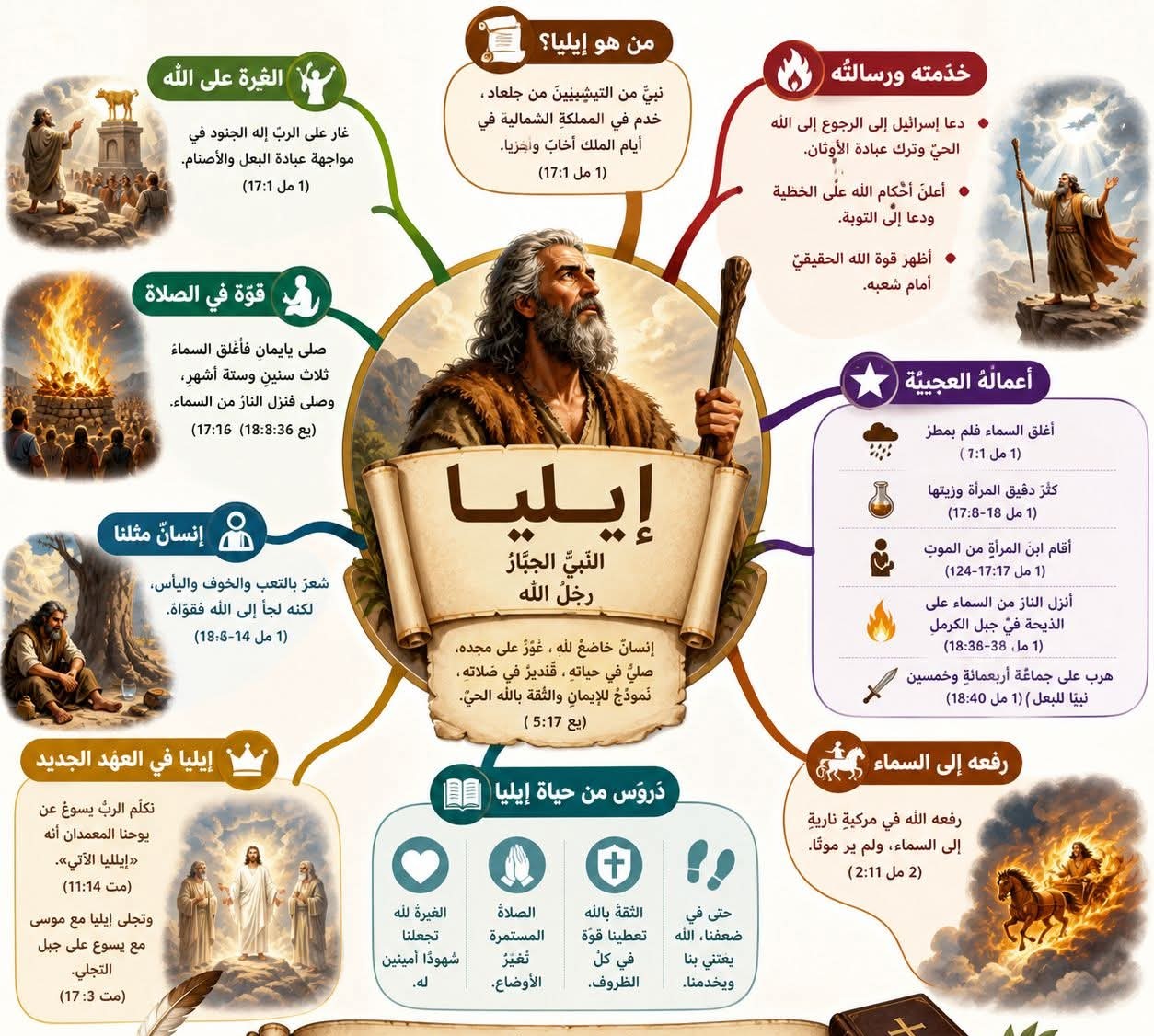
 شخصية "إيليا النبي"
شخصية "إيليا النبي" من أهم الأحداث في حياة إيليا
من أهم الأحداث في حياة إيليا